Interpretable and Globally Optimal Prediction for Textual Grounding using Image Concepts
Raymond A. Yeh1 Jinjun Xiong2 Wen-mei W. Hwu1 Minh N. Do1 Alexander G. Schwing1
1. University of Illinois Urbana-Champaign 2. IBM Thomas J. Watson Research Center
Abstract
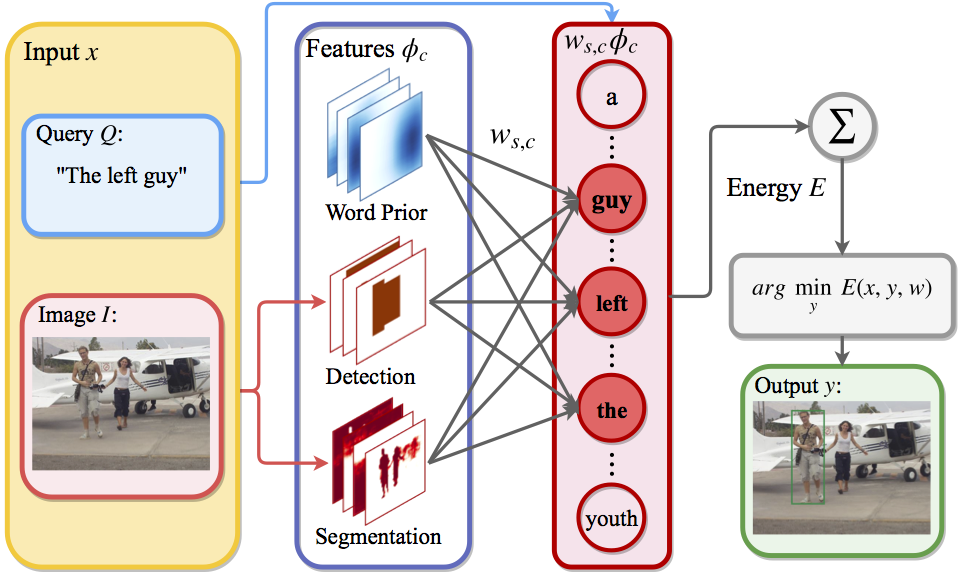
Textual grounding is an important but challenging task for human-computer interaction, robotics and knowledge mining. Existing algorithms generally formulate the task as selection of the solution from a set of bounding box proposals obtained from deep net based systems. In this work, we demonstrate that we can cast the problem of textual grounding into a unified framework that permits efficient search over all possible bounding boxes. Hence, we able to consider significantly more proposals and, due to the unified formulation, our approach does not rely on a successful first stage. Beyond, we demonstrate that the trained parameters of our model can be used as word-embeddings which capture spatial-image relationships and provide interpretability. Lastly, our approach outperforms the current state-of-the-art methods on the Flickr 30k Entities and the ReferItGame dataset by 3.08% and 7.77% respectively.
Materials


Presentation
Citation
@inproceedings{YehNIPS2017,
author = {R.~A. Yeh and J. Xiong and W.-M. Hwu and M. Do and A.~G. Schwing},
title = {Interpretable and Globally Optimal Prediction for Textual Grounding using Image Concepts},
booktitle = {Proc. NIPS},
year = {2017},
}