Semantic Image Inpainting with Deep Generative Models
Raymond A. Yeh*
Chen Chen*
Teck Yian Lim
Alexander G. Schwing
Mark Hasegawa-Johnson
Minh N. Do
* indicating equal contribution.
University of Illinois Urbana-Champaign
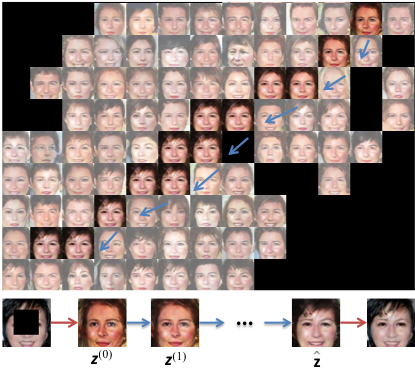
Abstract
Semantic image inpainting is a challenging task where large missing regions have to be filled based on the available visual data. Existing methods which extract information from only a single image generally produce unsatisfactory results due to the lack of high level context. In this paper, we propose a novel method for semantic image inpainting, which generates the missing content by conditioning on the available data. Given a trained generative model, we search for the closest encoding of the corrupted image in the latent image manifold using our context and prior losses. This encoding is then passed through the generative model to infer the missing content. In our method, inference is possible irrespective of how the missing content is structured, while the state-of-the-art learning based method requires specific information about the holes in the training phase. Experiments on three datasets show that our method successfully predicts information in large missing regions and achieves pixel-level photorealism, significantly outperforming the state-of-the-art methods.
Materials


Code
Results

Citation
@inproceedings{
yeh2017semantic,
title={Semantic Image Inpainting with Deep Generative Models},
author={Yeh$^\ast$, Raymond A. and Chen$^\ast$, Chen and Lim, Teck Yian and Schwing Alexander G. and Hasegawa-Johnson, Mark and Do, Minh N.},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2017},
note = {$^\ast$ equal contribution}
}