Unsupervised Textual Grounding: Linking Words to Image Concepts
Raymond A. Yeh Minh N. Do Alexander G. Schwing
University of Illinois Urbana-Champaign
Abstract
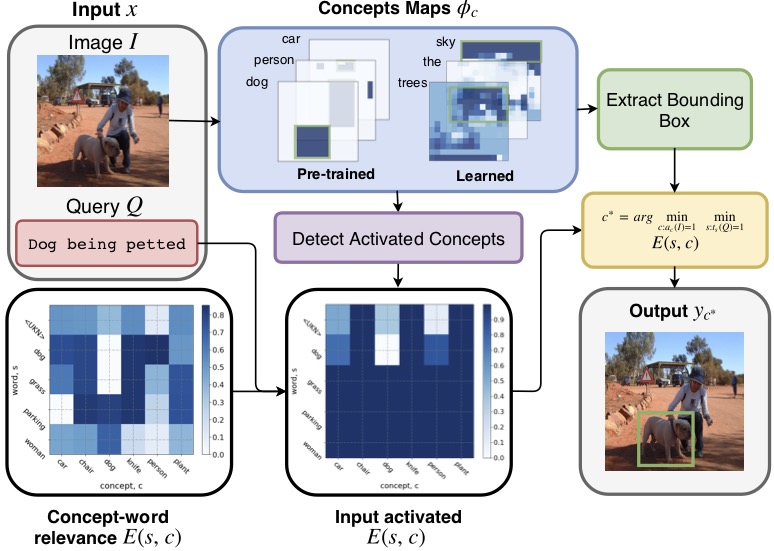
Textual grounding, i.e., linking words to objects in images, is a challenging but important task for robotics and human-computer interaction. Existing techniques benefit from recent progress in deep learning and generally formulate the task as a supervised learning problem, selecting a bounding box from a set of possible options. To train these deep net based approaches, access to a large-scale datasets is required, however, constructing such a dataset is time-consuming and expensive. Therefore, we develop a completely unsupervised mechanism for textual grounding using hypothesis testing as a mechanism to link words to detected image concepts. We demonstrate our approach on the ReferIt Game dataset and the Flickr30k data, outperforming baselines by 7.98% and 6.96% respectively.
Materials


Presentation
Citation
@inproceedings{YehCVPR2018,
author = {R.~A. Yeh and M.~N. Do and A.~G. Schwing},
title = {Unsupervised Textual Grounding: Linking Words to Image Concepts},
booktitle = {Proc. CVPR},
year = {2018},
}